2.1 Overview
Current best practices in scRNA-Seq
- Perform QC by finding outlier peaks in the number of genes, the count depth and the fraction of mitochondrial reads. Consider these covariates jointly instead of separately.
- Be as permissive of QC thresholding as possible, and revisit QC if downstream clustering cannot be interpreted.
- If the distribution of QC covariates differ between samples, QC thresholds should be determined separately for each sample to account for sample quality differences
- We recommend scran for normalization of non-full-length datasets. An alternative is to evaluate normalization approaches via scone especially for plate-based datasets. Full-length scRNA-seq protocols can be corrected for gene length using bulk methods.
- There is no consensus on scaling genes to 0 mean and unit variance. We prefer not to scale gene expression.
- Normalized data should be log(x+1)-transformed for use with downstream analysis methods that assume data are normally distributed.
- Regress out biological covariates only for trajectory inference and if other biological processes of interest are not masked by the regressed out biological covariate.
- Regress out technical and biological covariates jointly rather than serially.
- Plate-based dataset pre-processing may require regressing out counts, normalization via non-linear normalization methods or downsampling.
- We recommend performing batch correction via ComBat when cell type and state compositions between batches are consistent
- Data integration and batch correction should be performed by different methods. Data integration tools may over-correct simple batch effects.
- Users should be cautious of signals found only after expression recovery. Exploratory analysis may be best performed without this step.
- We recommend selecting between 1,000 and 5,000 highly variable genes depending on dataset complexity.
- Feature selection methods that use gene expression means and variances cannot be used when gene expression values have been normalized to zero mean and unit variance, or when residuals from model fitting are used as normalized expression values. Thus, one must consider what pre-processing to perform before selecting HVGs.
- Dimensionality reduction methods should be considered separately for summarization and visualization.
- We recommend UMAP for exploratory visualization; PCA for general purpose summarization; and diffusion maps as an alternative to PCA for trajectory inference summarization.
- PAGA with UMAP is a suitable alternative to visualize particularly complex datasets.
- Use measured data for statistical testing, corrected data for visual comparison of data and reduced data for other downstream analysis based on finding the underlying biological data manifold.
- We recommend clustering by Louvain community detection on a single-cell KNN graph.
- Clustering does not have to be performed at a single resolution. Subclustering particular cell clusters is a valid approach to focus on more detailed substructures in a dataset.
- Do not use marker gene P-values to validate a cell-identity cluster, especially when the detected marker genes do not help to annotate the community. P-values may be inflated.
- Note that marker genes for the same cell-identity cluster may differ between datasets purely due to dataset cell type and state compositions.
- If relevant reference atlases exist, we recommend using automated cluster annotation combined with data-derived marker-gene-based manual annotation to annotate clusters.
- Consider that statistical tests over changes in the proportion of a cell-identity cluster between samples are dependent on one another.
- Inferred trajectories do not have to represent a biological process. Further sources of evidence should be collected to interpret a trajectory.
- DE testing should not be performed on corrected data (denoised, batch corrected, etc.), but instead on measured data with technical covariates included in the model.
- Users should not rely on DE testing tools to correct models with confounded covariates. Model specification should be performed carefully ensuring a full-rank design matrix.
- We recommend using MAST or limma for DE testing.
- Users should be wary of uncertainty in the inferred regulatory relationships. Modules of genes that are enriched for regulatory relationships will be more reliable than individual edges.
Luecken & Theis (2019)
Best practices for single-cell analysis across modalities
Heumos et al. (2023)
What information should be included in an scRNA-Seq publication?
Füllgrabe et al. (2020)
Open problems in single-cell analysis
Luecken et al. (2025)
2.2 Experimental design
Experimental Considerations for Single-Cell RNA Sequencing Approaches
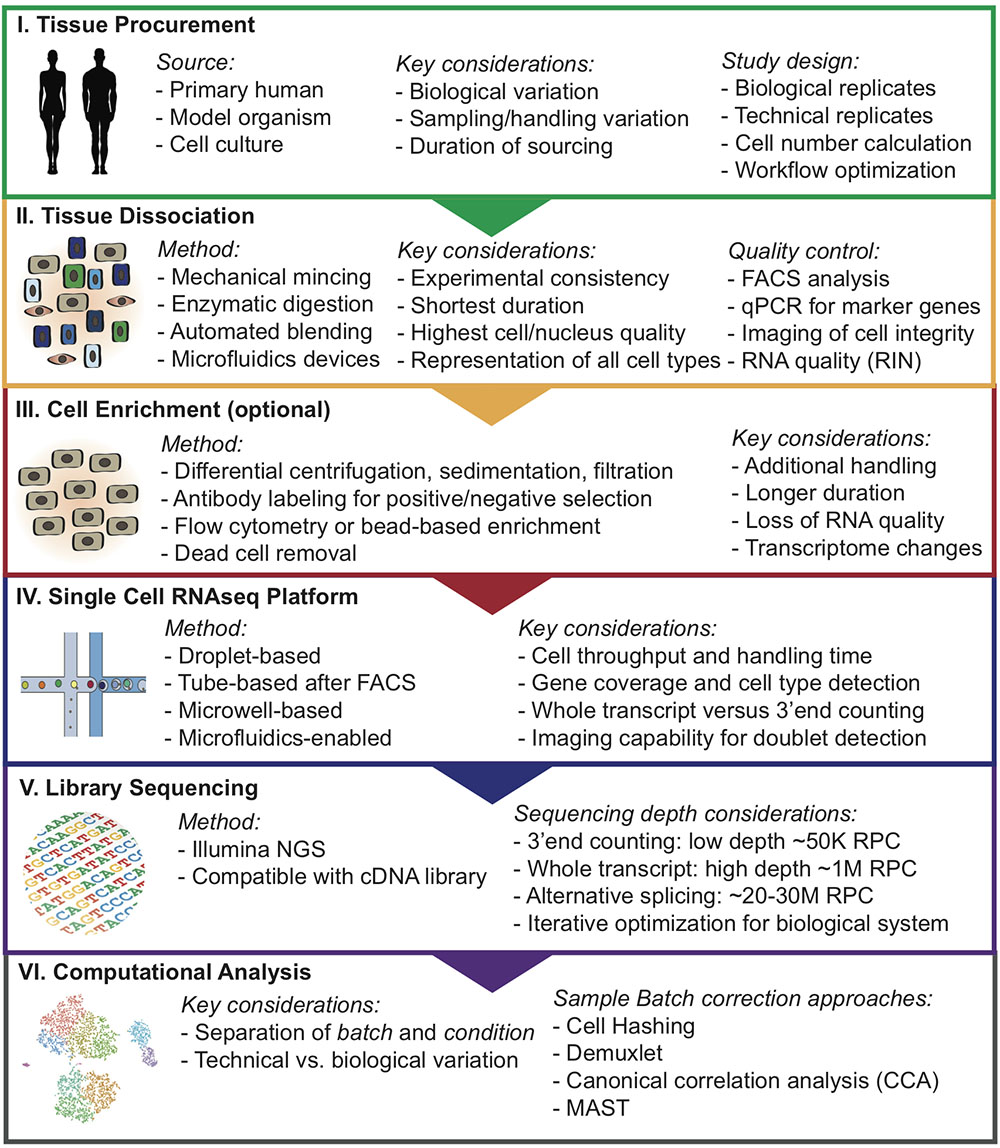
Nguyen et al. (2018)
How many reads are needed per cell? Sequencing depth?
Given a fixed budget, sequencing as many cells as possible at approximately one read per cell per gene is optimal, both theoretically and experimentally.
Zhang et al. (2020)
- scDesign (R) Li & Li (2019)
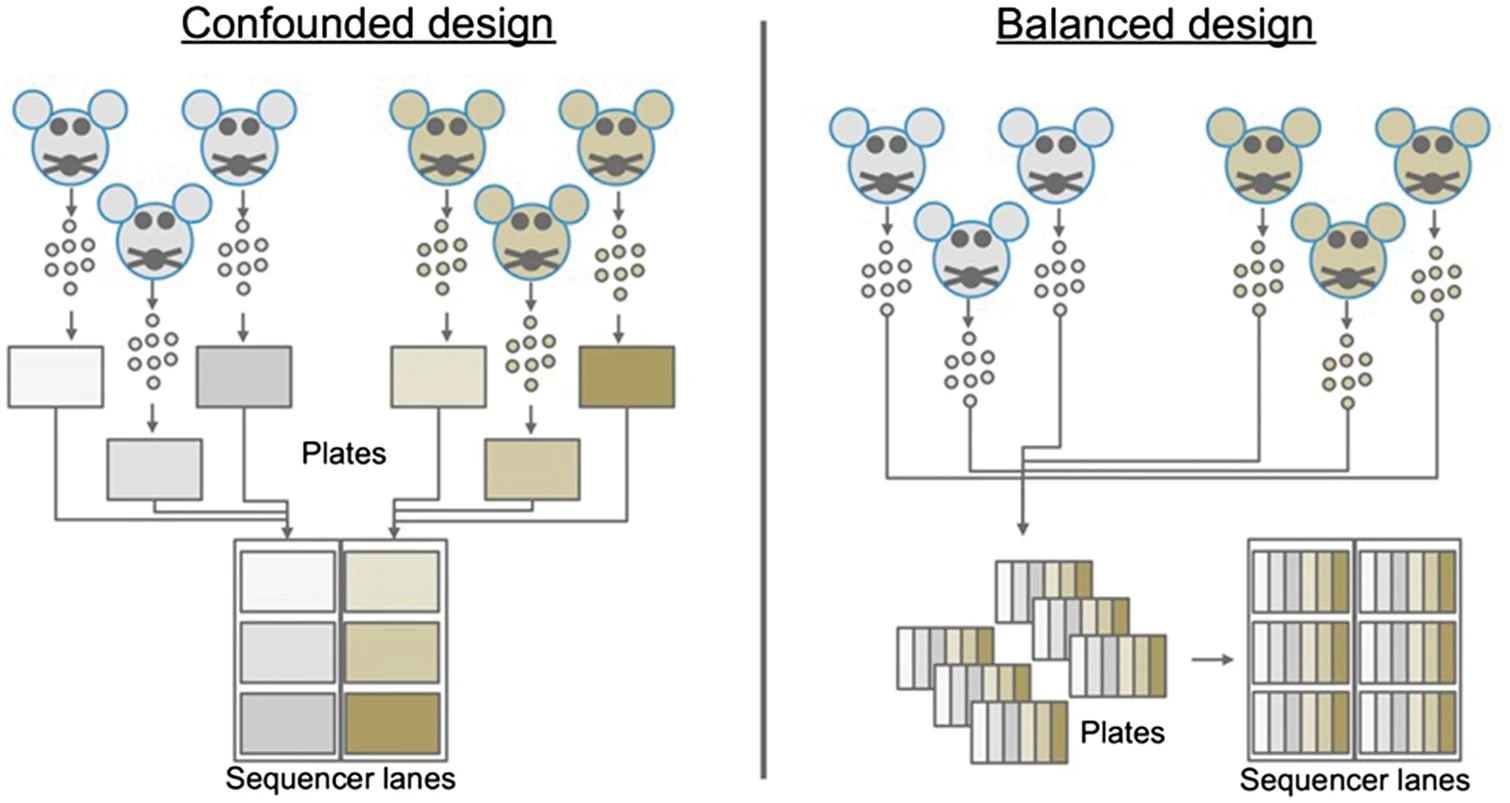
2.2.1 Batch design, number of cells
Avoid technical biases.
Deciding appropriate cell numbers
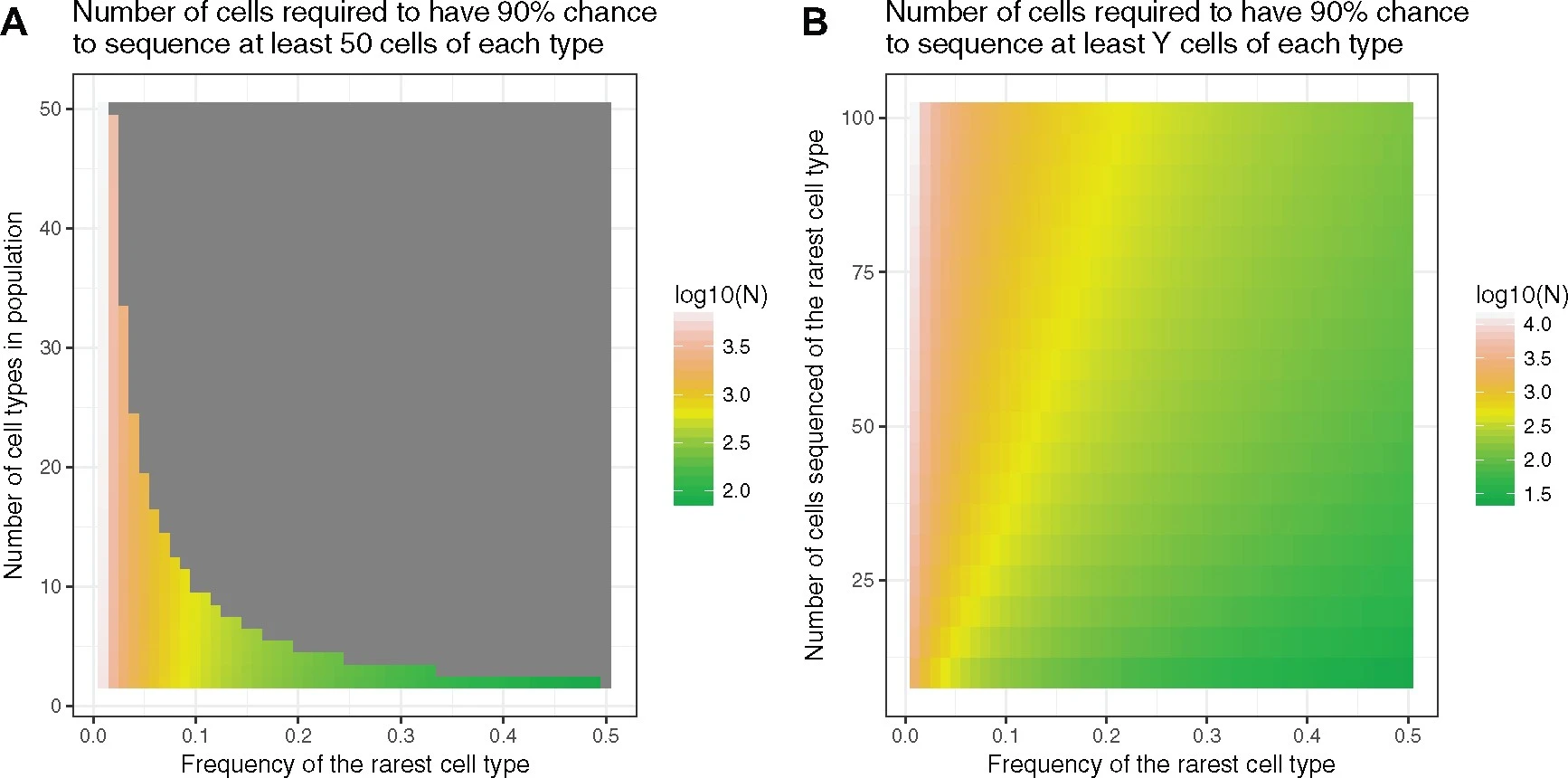
Baran-Gale et al. (2018)
- SatijaLab Cells Calculator
- SCOPIT (Shiny app)
- powsimR (R)
2.2.2 Sequencing depth
While 250 000 reads per cell are sufficient for accuracy, 1 million reads per cell were a good target for saturated gene detection.
Svensson et al. (2017)
2.3 Methods and kits
Common methods for single-cell RNA-seq are based on microfluidics, droplets, microwells, or FACS sorting into plates. The most popular platforms are 10X Genomics Chromium, Drop-seq, inDrop, Seq-Well, and SMART-seq2/3. Parse has recently emerged as a new droplet-based platform.
Droplet based methods are high-throughput and cost-effective, but they typically capture only the 3’ or 5’ end of transcripts and have lower sensitivity per cell. Plate-based methods like SMART-seq2/3 provide full-length transcript coverage and higher sensitivity but are lower throughput and more expensive per cell.
How do 10X Genomics and Parse compare?
- Hardware/cost: 10x needs a Chromium Controller; Parse doesn’t (lower setup cost) but is more hands‑on. 10x prone to GEM wetting/clogging; Parse avoids this.
- Workflow: 10x ≈3 days and more flexible; Parse ≥4 days with a long uninterrupted day. Parse supports fixation/storage without extra hardware; 10x fixation needs another instrument.
- Multiplexing: Built‑in with Parse; 10x requires add‑on reagents/steps (e.g., hashing).
- Input/recovery: Parse needs ≥100k cells/sample; 10x can run ~800 cells. 10x generally higher, more consistent recovery—better for rare populations.
- Read composition/ambient RNA: Parse slightly higher mitochondrial %; 10x much higher ribosomal/lncRNA (more ambient RNA). Parse washes reduce ambient RNA.
- Doublets: This study—10x with hashing ~14%; Parse ~31% (WT) and ~21% (mini); literature mixed by tissue.
- Sensitivity/reproducibility: Parse detects ~2× more genes at similar depth but shows higher variability and batch effects; 10x more reproducible and simpler downstream (less batch correction).
- Cell‑type resolution (thymus): 10x cleanly resolves major subsets and DP subtypes; Parse struggled (aberrant Cd3d/Cd3g, missed DP‑A, poor SP‑CD4 vs SP‑CD8 separation).
- Bottom line: Choose 10x for reliability, recovery, and annotation with low input; choose Parse for no instrument, integrated multiplexing, fixation flexibility, and higher gene detection at the cost of longer workflow and variable data.
Filippov et al. (2024)
- Overall: Both produced high-quality PBMC data with consistent replicates.
- Efficiency: 10x ≈2× higher cell recovery and ~13% more valid reads; Parse needs more input and deeper sequencing (more invalid barcodes).
- Multiplets/QC: Parse had lower multiplet rates → fewer cells discarded than 10x.
- Sensitivity (20k reads/cell): Parse detected ~1.2× more genes in T/NK/B; no advantage in monocytes.
- Biases: 10x enriched for ribosomal protein-coding genes; 10x GC bias varies by chemistry.
- Downstream: Parse improved clustering/rare-cell detection but showed weaker marker-gene expression—reference-based annotation recommended.
- Use-cases: Parse for high-throughput multiplexing and low-expression genes; 10x for higher recovery/valid reads and robust marker quantification; overall quality comparable.
2.4 Mapping and Quantification
2.4.1 CellRanger
Process chromium data
BCL to FASTQ
FASTQ to cellxgene counts
Feature barcoding
2.4.2 Kallisto Bustools
10x, inDrop and Dropseq
Generate cellxgene, cellxtranscript matrix
RNA velocity data
Feature barcoding
QC reports
Melsted et al. (2019)
2.4.3 Salmon Alevin
- Drop-seq, 10x-Chromium v1/2/3, inDropV2, CELSeq 1/2, Quartz-Seq2, sci-RNA-seq3
- Generate cellxgene matrix
- Alevin
2.4.4 Nextflow nf-core rnaseq
- Bulk RNA-Seq, SMART-Seq
- QC, trimming, UMI demultiplexing, mapping, quantification
- cellxgene matrix
- nf-core scrnaseq
2.5 Background correction
Identification and correction for free RNA background contamination in single-cell RNA-seq data.
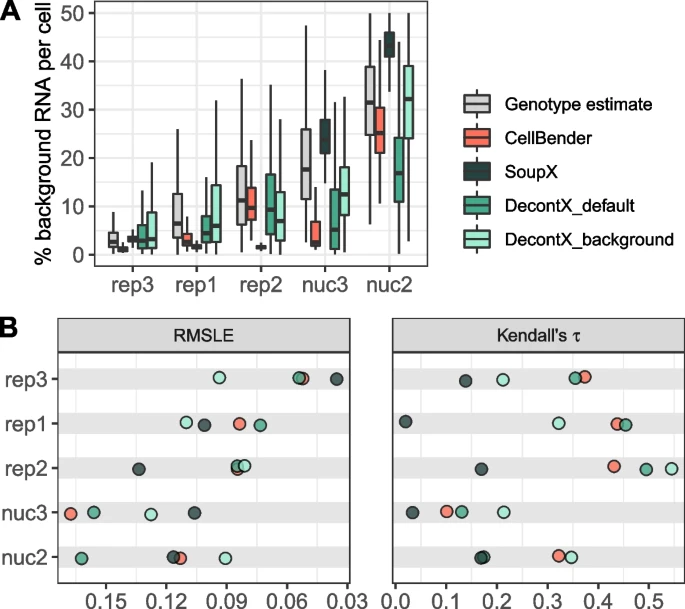
Janssen et al. (2023)
Tools
- SoupX (R)
- decontX (R)
- CellBender (Python)
CellBender is slow when using CPU.
2.6 Doublet detection

The methods include doubletCells, Scrublet, cxds, bcds, hybrid, Solo, DoubletDetection, DoubletFinder, and DoubletDecon. Evaluation was conducted using 16 real scRNA-seq datasets with experimentally annotated doublets and 112 synthetic datasets.
- Evaluation Metrics
- Detection Accuracy: Assessed using the area under the precision-recall curve (AUPRC) and the area under the receiver operating characteristic curve (AUROC).
- Impact on Downstream Analyses: Effects on differential expression (DE) gene analysis, highly variable gene identification, cell clustering, and cell trajectory inference.
- Computational Efficiency: Considered aspects such as speed, scalability, stability, and usability.
- Key Findings
- Detection Accuracy: DoubletFinder achieved the highest detection accuracy among the methods.
- Downstream Analyses: Removal of doublets generally improved the accuracy of downstream analyses, with varying degrees of improvement depending on the method.
- Computational Efficiency: cxds was found to be the most computationally efficient method, particularly excelling in speed and scalability.
- Performance Factors
- Doublet Rate: Higher doublet rates improved the accuracy of all methods.
- Sequencing Depth: Greater sequencing depth led to better performance.
- Number of Cell Types: More cell types generally resulted in better detection accuracy, except for cxds, bcds, and hybrid methods.
- Cell-Type Heterogeneity: Higher heterogeneity between cell types improved the detection accuracy for most methods.
Overall Conclusion: DoubletFinder is recommended for its high detection accuracy and significant improvement in downstream analyses, while cxds is highlighted for its computational efficiency.
Xi & Li (2021)
For 10X data, the expected odublet rate is 0.8% per 1000 cells for 10x 3’ CellPlex kit and 0.4% per 1000 cells for high-throughput (HT) 3’ v3.1 assay a, b.
The doublet rate is 3% per 100,000 cells for Parse WT kit as mentioned here.
| rate | cells_loaded | cells_recovered |
|---|---|---|
| 0.4 | 825 | 500 |
| 0.8 | 1650 | 1000 |
| 1.6 | 3300 | 2000 |
| 2.4 | 4950 | 3000 |
| 3.2 | 6600 | 4000 |
| 4.0 | 8250 | 5000 |
| 4.8 | 9900 | 6000 |
| 5.6 | 11550 | 7000 |
| 6.4 | 13200 | 8000 |
| 7.2 | 14850 | 9000 |
| 8.0 | 16500 | 10000 |
- scDBlFinder (R)
- DoubletFinder (R)
- Scrublet (Python)
2.7 Cell type prediction
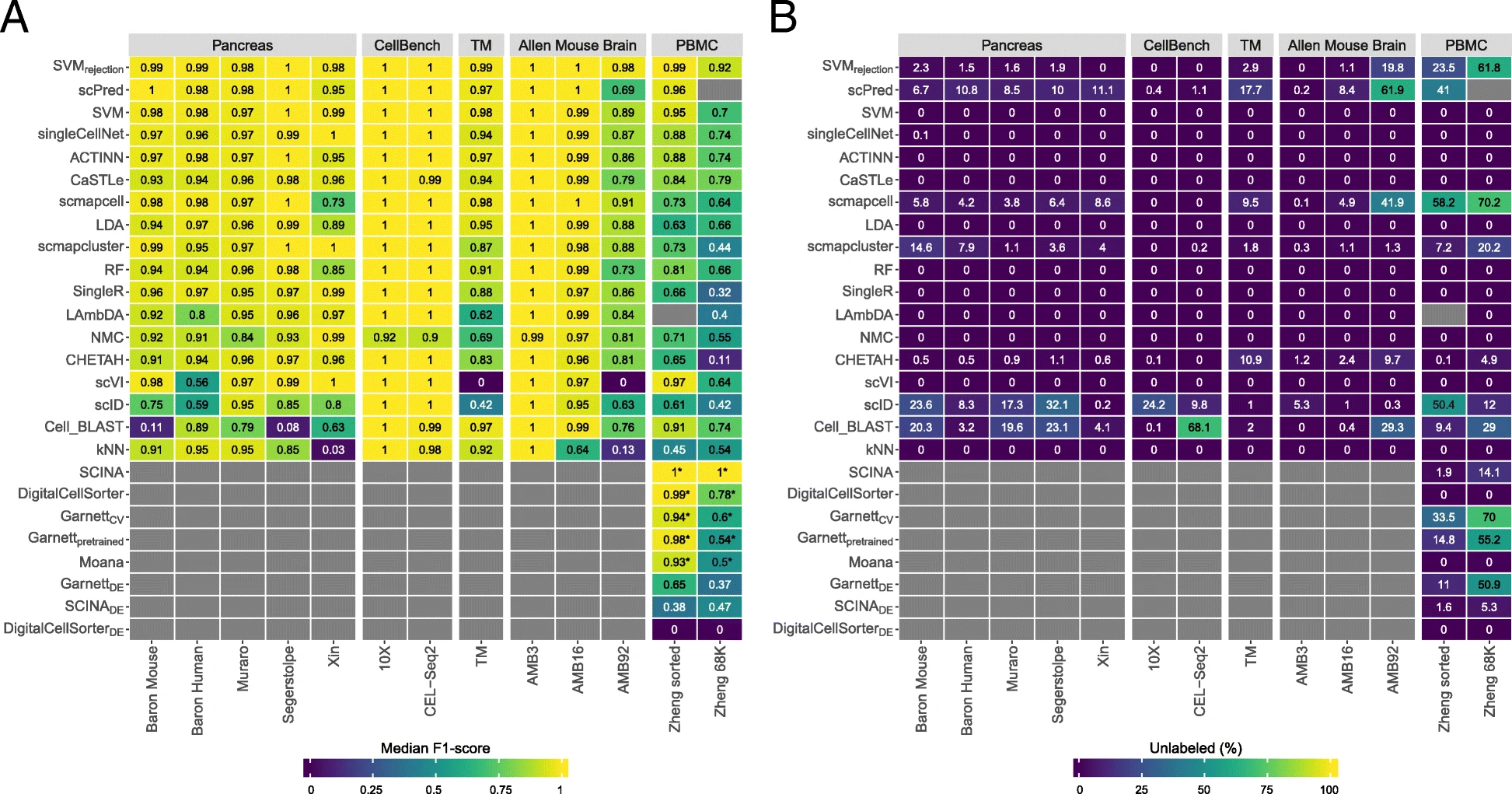
- Benchmarked 22 supervised classification methods for automatic cell identification in scRNA-seq, including both single-cell-specific tools and general-purpose ML classifiers.
- Used 27 public scRNA-seq datasets spanning different sizes, technologies, species, and annotation complexity.
- Evaluated two main scenarios: within-dataset (intra-dataset) and across-dataset (inter-dataset) prediction.
- Scored methods by accuracy, fraction of unclassified cells, and computation time, and also tested sensitivity to feature selection and number of cells per population.
- Found most methods perform well broadly, but accuracy drops for complex datasets with overlapping classes or very fine (“deep”) annotation levels.
- Reported that a general-purpose support vector machine (SVM) achieved the best overall performance across their experiments.
- Released code and a Snakemake workflow to reproduce/extend the benchmark (new methods and datasets).
Abdelaal et al. (2019)
Identification of cell types can be completely automated (by comparing to reference data/databases) or semi-automated (reference data + marker genes).

- Compares 32 methods using common performance criteria such as prediction accuracy, F1-score, “unlabeling” rate (cells left unassigned), and computational efficiency.
- Organizes methods by major strategy families, including marker/gene-set–based approaches, reference-based label transfer, and supervised machine-learning classifiers.
- Highlights that method performance is dataset-dependent, with challenges increasing when cell types are highly similar, labels are very fine-grained, or references are incomplete.
- Emphasizes practical selection factors beyond accuracy, especially whether a method can leave cells “unknown/unassigned,” how sensitive it is to batch effects, and how well it scales to large datasets.
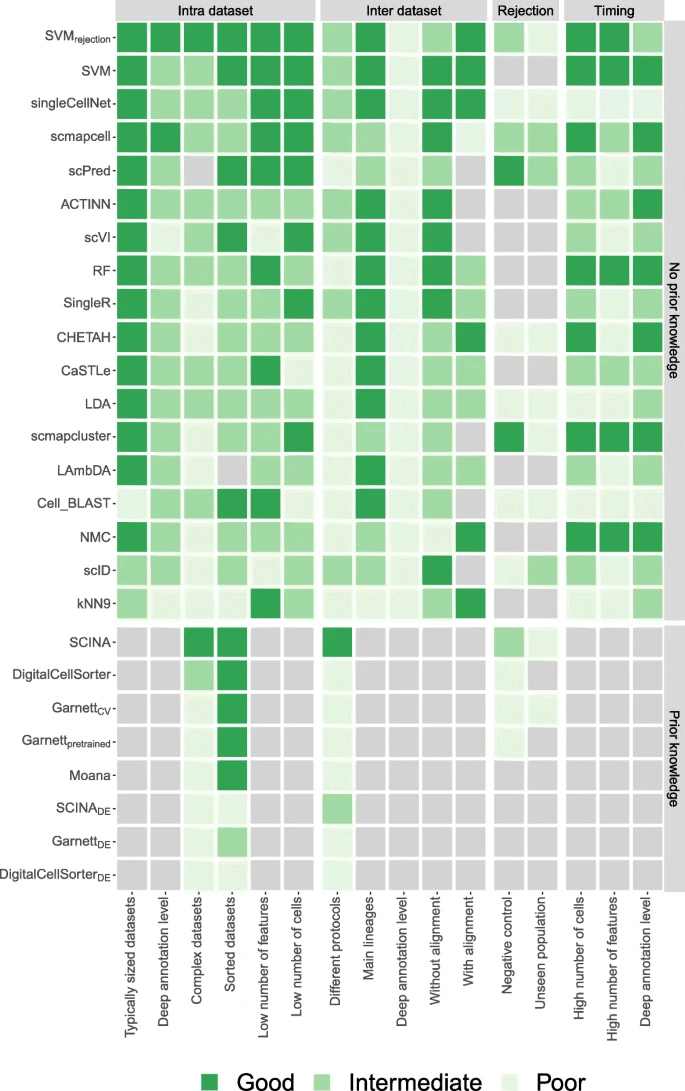
Xie et al. (2021)
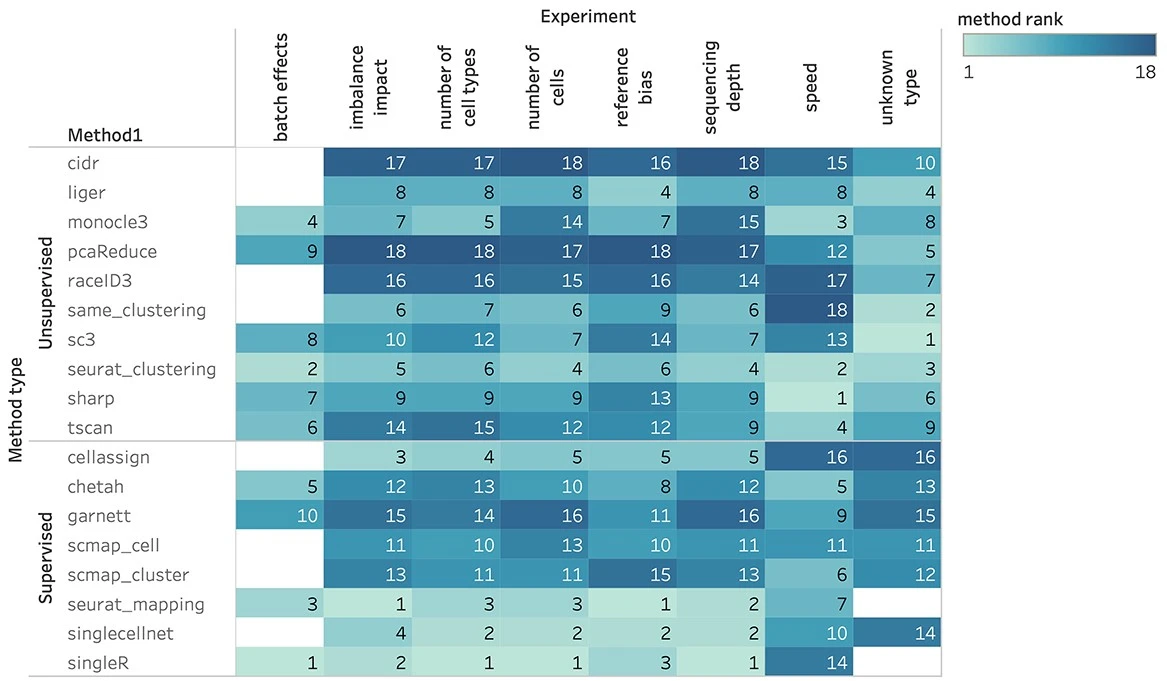
- Compared 8 supervised and 10 unsupervised scRNA-seq cell type identification methods across 14 real public datasets (different tissues, protocols, species).
- Main result: supervised methods usually outperform unsupervised methods, except when the goal is identifying unknown/novel cell types (where unsupervised tends to do better).
- Supervised methods work best when the reference is high-quality, low-complexity, and similar to the query; performance drops as reference bias increases (different individuals/conditions/batches/species).
- Dataset complexity is a major driver: when complexity is low, supervised wins clearly; when complexity is high, supervised vs unsupervised performance becomes more similar and can even reverse under strong reference bias.
- More training cells generally improve supervised performance until a saturation point; unsupervised results can vary strongly with sample size because cluster-number estimation changes with dataset size.
- Sequencing depth helps both categories up to a saturation point; deeper data improves results most when baseline depth is low.
- Batch-effect correction was often not necessary and could hurt performance; most supervised methods did not improve after correction, with CHETAH being a notable exception due to fewer “unassigned” calls.
- Increasing the number of cell types and stronger cell-type similarity makes the task harder; unsupervised methods are particularly sensitive when the inferred cluster number disagrees with the true number.
- With imbalanced populations, supervised methods are generally more robust if the training set contains enough examples of rare types; unsupervised performance is affected by imbalance and cluster-number errors.
- Compute/scalability: unsupervised methods are generally faster; among fast methods, several could handle ~50k cells quickly, and experiments on ~600k cells showed similar trends to smaller datasets.
- Method-level takeaways highlighted in the paper: among supervised methods, Seurat v3 mapping and SingleR were top overall (Seurat mapping favored for large datasets due to speed), and among unsupervised methods, Seurat v3 clustering was strongest overall, with SHARP recommended for ultra-large datasets.
Sun et al. (2022)
It is also important that cell types are labelled with the same labels across datasets and studies. It is useful to refer to a cell type ontology Cell type ontology.
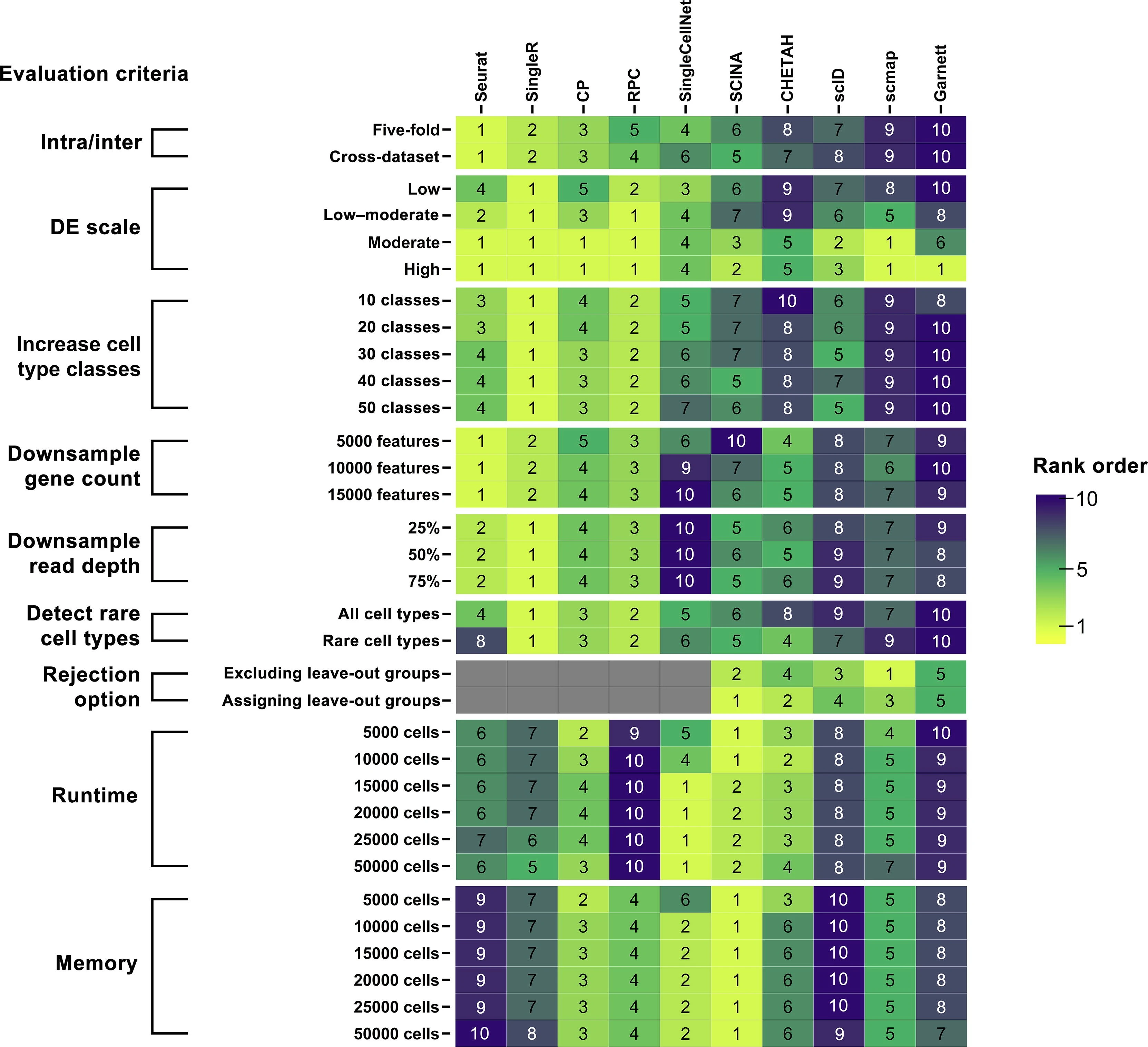
- Benchmarked 10 R packages for automated scRNA-seq cell-type annotation: Seurat, scmap, SingleR, CHETAH, SingleCellNet, scID, Garnett, SCINA, plus two repurposed methylation deconvolution methods (CP, RPC).
- Evaluated accuracy on real datasets (PBMC, pancreas, Tabula Muris full and lung subsets) and multiple simulation suites; metrics included overall accuracy, ARI, and V-measure.
- Overall top performers were Seurat, SingleR, CP, RPC, and SingleCellNet; Seurat was best at annotating major cell types in both intra-dataset and inter-dataset tests.
- Inter-dataset annotation is harder and performance is dataset-dependent; PBMC is particularly challenging due to highly similar immune subtypes (e.g., CD4 vs CD8 T cells).
- For highly similar cell types (low DE simulations), all methods degrade, but SingleR and RPC were most robust; Seurat was weaker under the hardest similarity setting.
- As the number of cell-type classes increases (10→50), most methods drop in accuracy; SingleR stays extremely robust and RPC is consistently second-best, while Seurat deteriorates faster after ~30 classes.
- With gene/feature downsampling, Seurat and SingleR remain most stable (high ARI across reduced feature sets), whereas some methods (e.g., Garnett, scID, scmap) are more sensitive.
- Rare cell types: Seurat and SingleCellNet lose accuracy when rare groups get very small (≤50 cells in their rare-type simulations), while SingleR/CP/RPC are more robust.
- “Unknown”/rejection option: among methods that can label “unknown” (Garnett, SCINA, scmap, CHETAH, scID), SCINA had a relatively better balance for rejecting absent types, but rejection-enabled tools were not top overall for accuracy/robustness.
- Compute trade-offs: SingleCellNet and CP were fastest/most memory-efficient among top-accuracy tools; Seurat can be memory-heavy at large scale (reported up to ~100 GB at 50k cells) and RPC can be slow (hours) at large scale.
- Practical guidance: use Seurat for general annotation of separable major types; prefer SingleR/RPC/CP when expecting rare populations, high similarity, or many labels (given a good reference).
Huang et al. (2021)
- SingleR (R)
- scPred (R)
- celltypist (Python)
- CHETAH (R)
- easybio (R) R access to CellMarker 2.0 database
- SCINA (R)
- Garnett (R)
- scmap (R)
- SingleCellNet (R)
- scID (R)
- cellassign (R)
- CellFishing (Julia)
2.8 Differential expression
- Comparison of DGE tools for single-cell data
All of the tools perform well when there is no multimodality or low levels of multimodality. They all also perform better when the sparsity (zero counts) is less. For data with a high level of multimodality, methods that consider the behavior of each individual gene, such as DESeq2, EMDomics, Monocle2, DEsingle, and SigEMD, show better TPRs. If the level of multimodality is low, however, SCDE, MAST, and edgeR can provide higher precision.
In general, the methods that can capture multimodality (non-parametric methods), perform better than do the model-based methods designed for handling zero counts. However, a model-based method that can model the drop-out events well, can perform better in terms of true positive and false positive. We observed that methods developed specifically for scRNAseq data do not show significantly better performance compared to the methods designed for bulk RNAseq data; and methods that consider behavior of each individual gene (not all genes) in calling DE genes outperform the other tools.
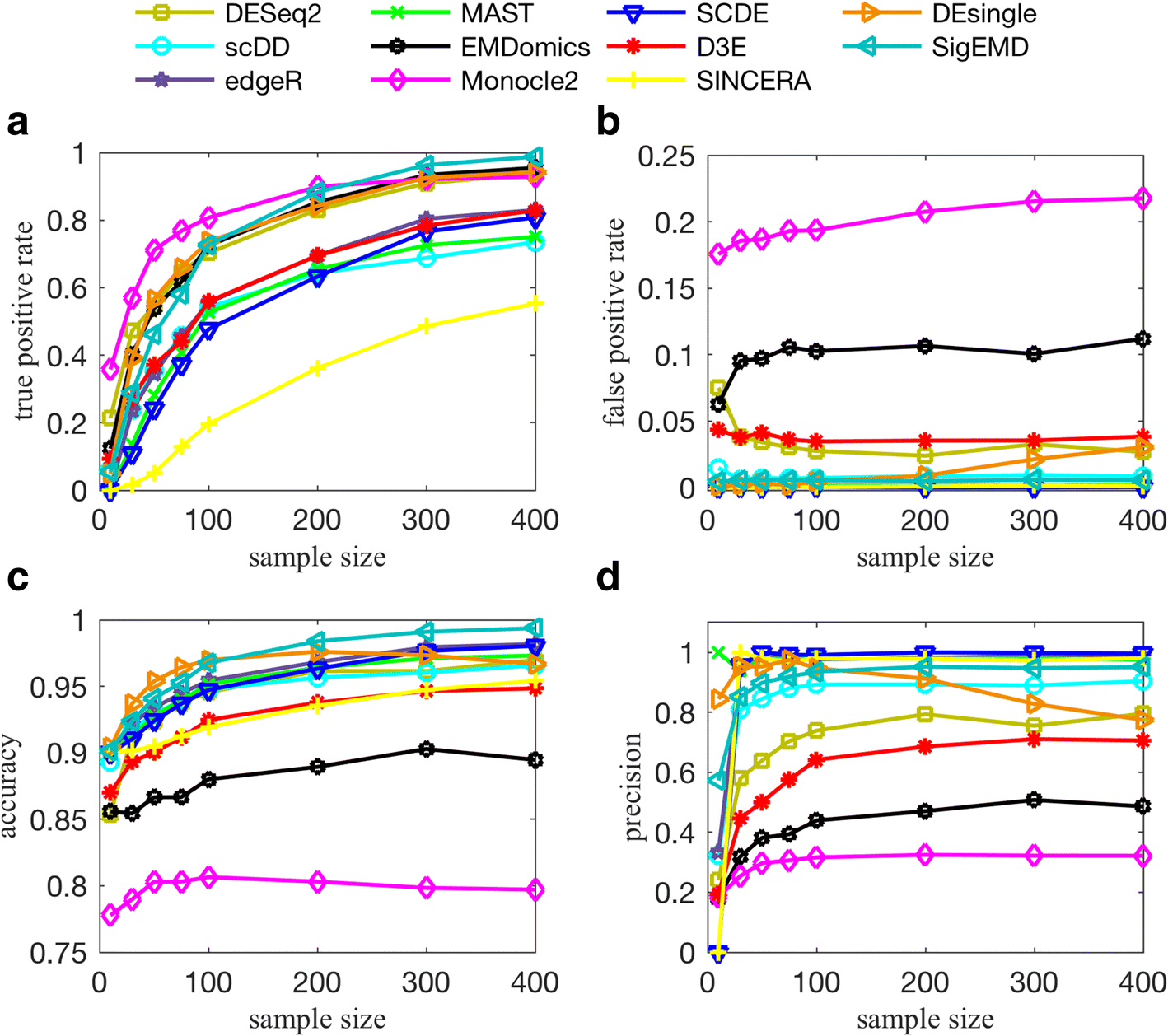
T. Wang et al. (2019)
- Differential expression without clustering or grouping
- singleCellHaystack
2.9 Data Integration
- Single-cell data integration challenges

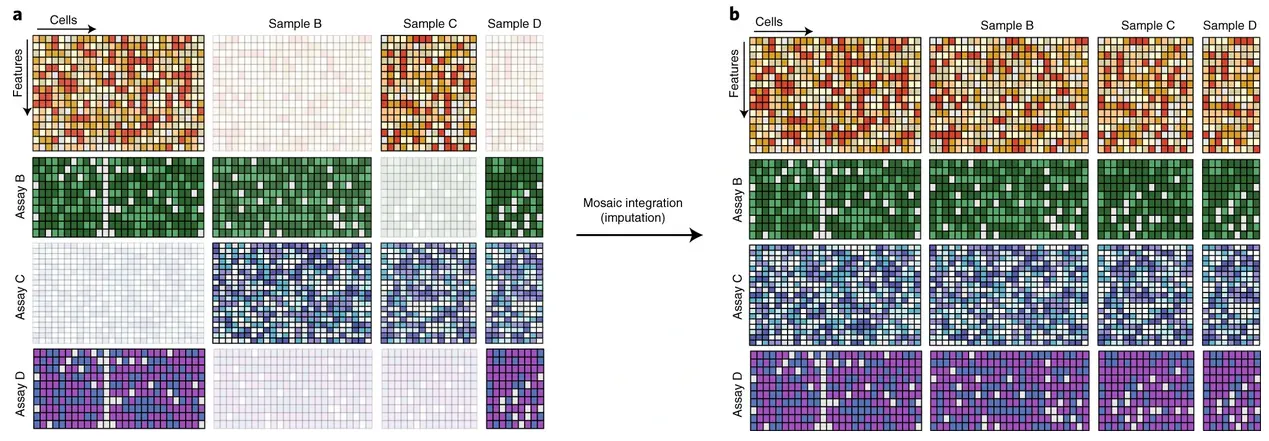
Argelaguet et al. (2021) Principles and challenges of data integration by Argelaguet
- Comparison of data integration methods
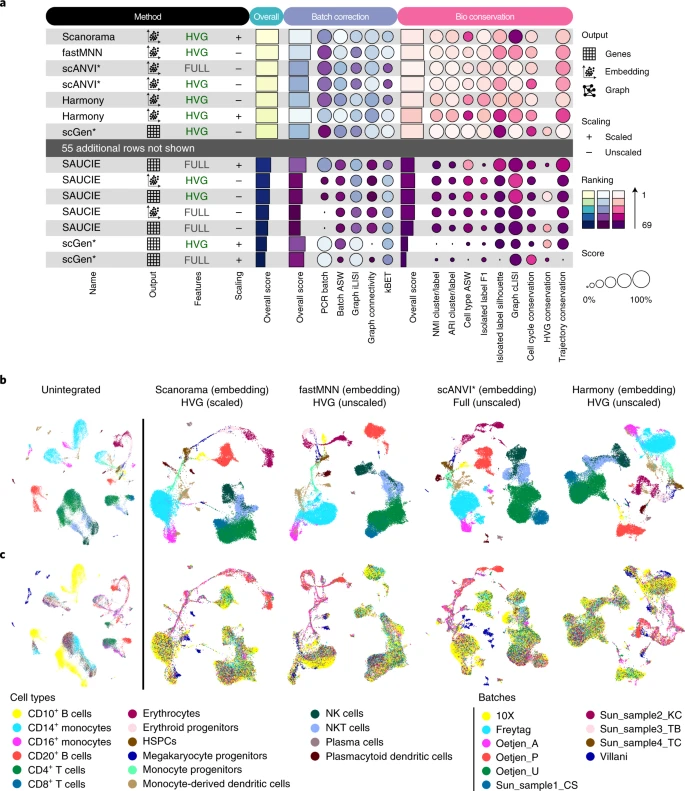
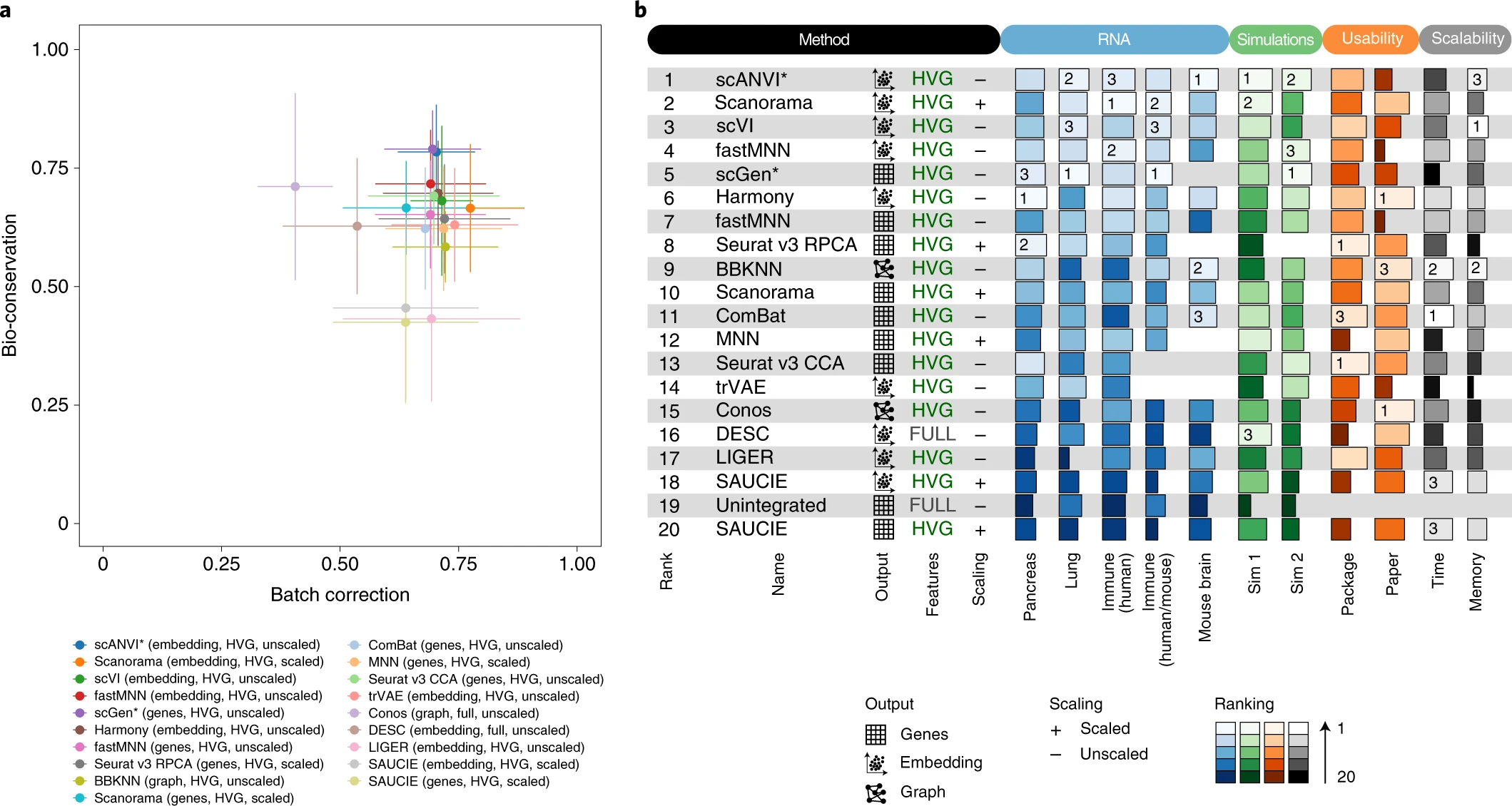
Luecken et al. (2022)
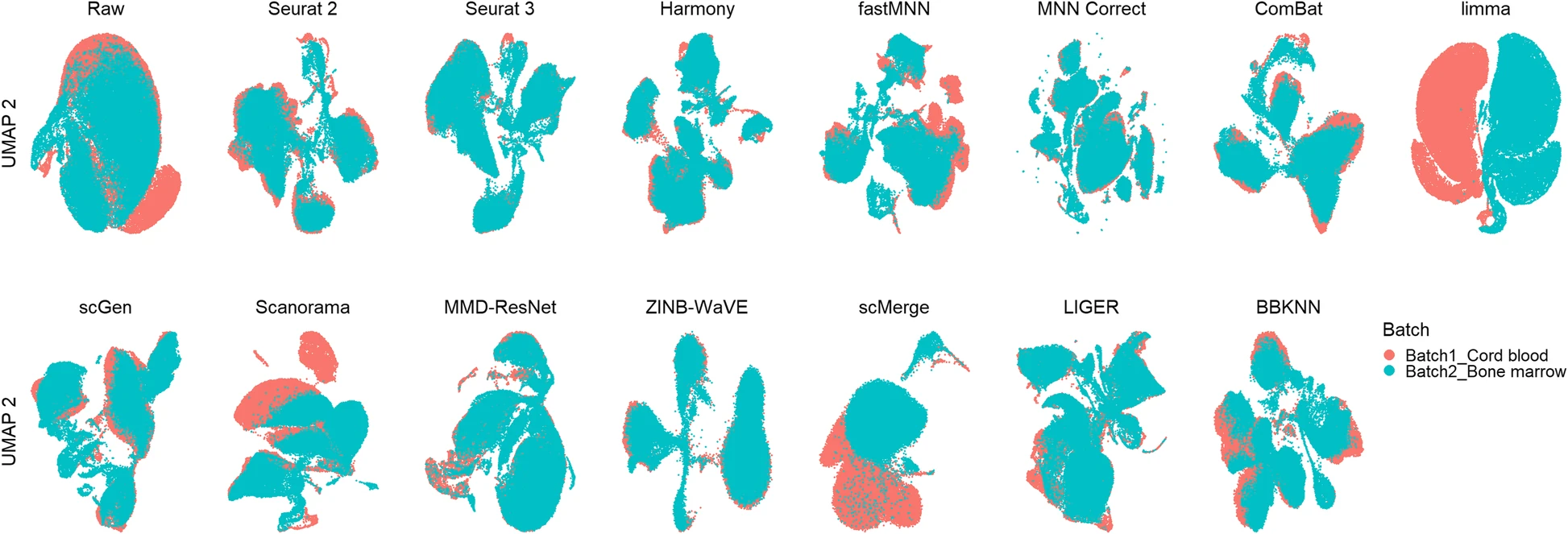
We tested 14 state-of-the-art batch correction algorithms designed to handle single-cell transcriptomic data. We found that each batch-effect removal method has its advantages and limitations, with no clearly superior method. Based on our results, we found LIGER, Harmony, and Seurat 3 to be the top batch mixing methods. Harmony performed well on datasets with common cell types, and also different technologies. The comparatively low runtime of Harmony also makes it suitable for initial data exploration of large datasets. Likewise, LIGER performed well, especially on datasets with non-identical cell types. The main drawback of LIGER is its longer runtime than Harmony, though it is acceptable for its performance. Seurat 3 is also able to handle large datasets, however with 20–50% longer runtime than LIGER. Due to its good batch mixing results with multiple batches, it is also recommended for such scenarios. To improve recovery of DEGs in batch-corrected data, we recommend scMerge for batch correction.
Feature selection methods affects the performance of integration. Zappia et al. (2025)
Comparison of Multiomic integration Xiao et al. (2024)
Tran et al. (2020)
- Seurat (R)
- Harmony (R)
- Liger (R)
- FastMNN (R)
- scVI (Python) Variational autoencoder framework for single-cell omics data analysis
- scANVI (Python) Semi-supervised version of scVI
- Scanorama (Python)
- STACAS (R) Andreatta et al. (2024)
- BBKNN
- scIntegrationMetrics (R) Metrics to evaluate batch effects and correction Andreatta et al. (2024)
- SCIB
- GLUE (R,Python) Diagonal integration
2.10 Trajectory

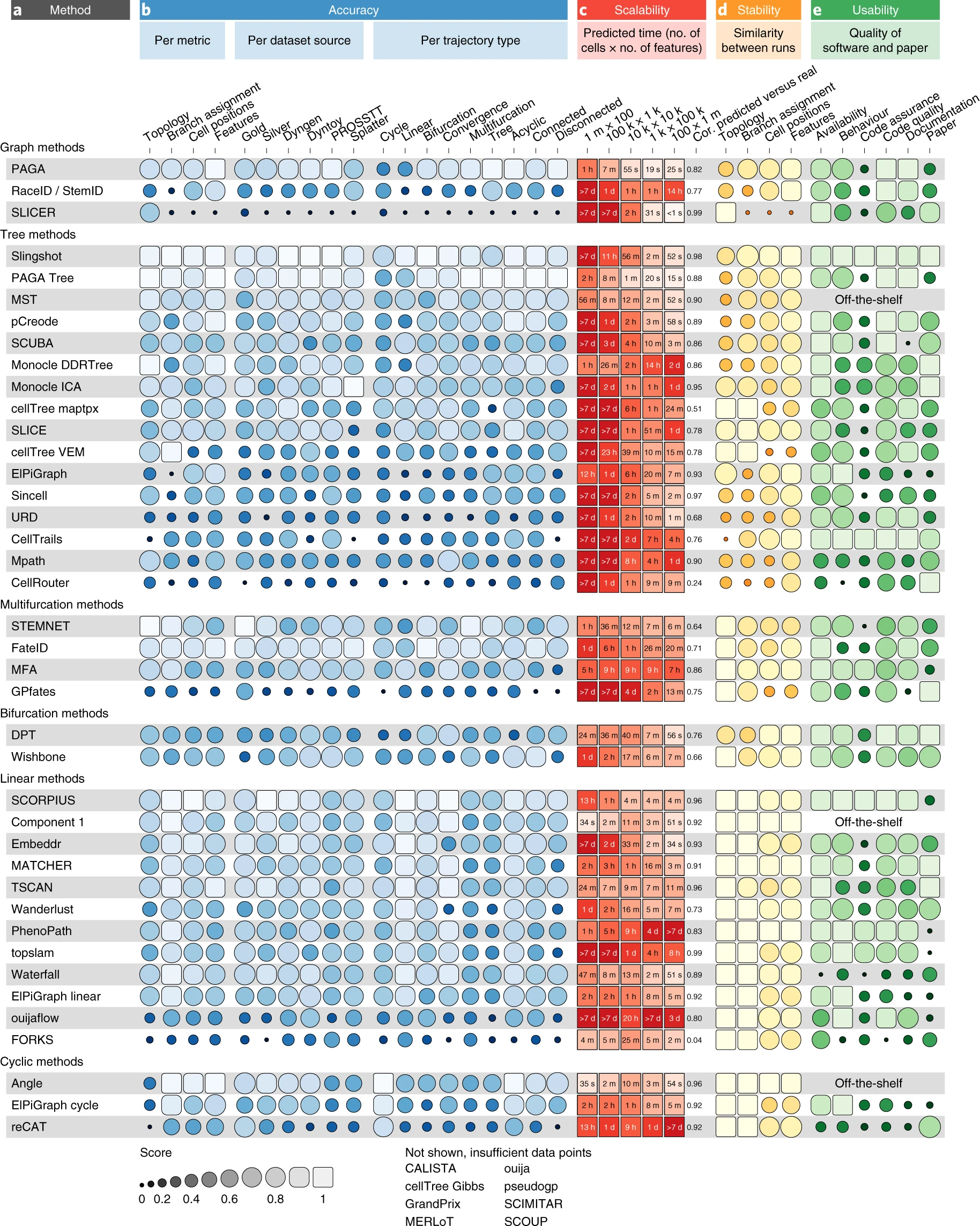
Saelens et al. (2019)
Standard trajectory tools
Multiomic trajectory tools
2.11 RNA velocity
Core Concepts and Mechanism
- RNA velocity is a computational method used to predict the future state of individual cells by analyzing the balance between unspliced (nascent) and spliced (mature) mRNA
- The method exploits the causal relationship between these two species: an abundance of unspliced mRNA suggests a gene is being upregulated, while its depletion suggests downregulation
- By combining these measurements across thousands of genes, researchers can reconstruct directed differentiation trajectories from “snapshot” single-cell data without needing prior knowledge of cell lineages
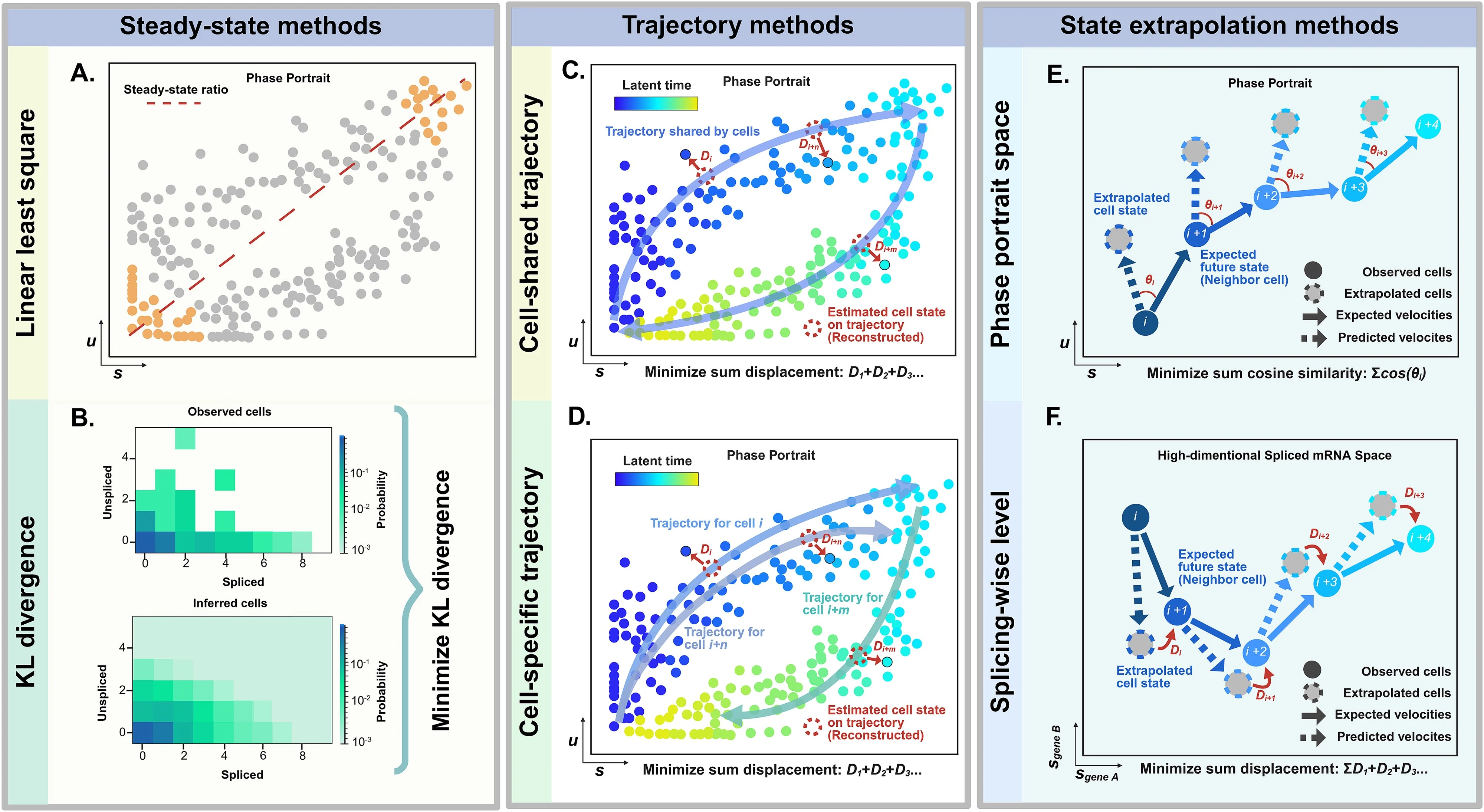
- The primary signal for RNA velocity is derived from the curvature in a “phase portrait,” which reflects the temporal delay between transcription, splicing, and degradation
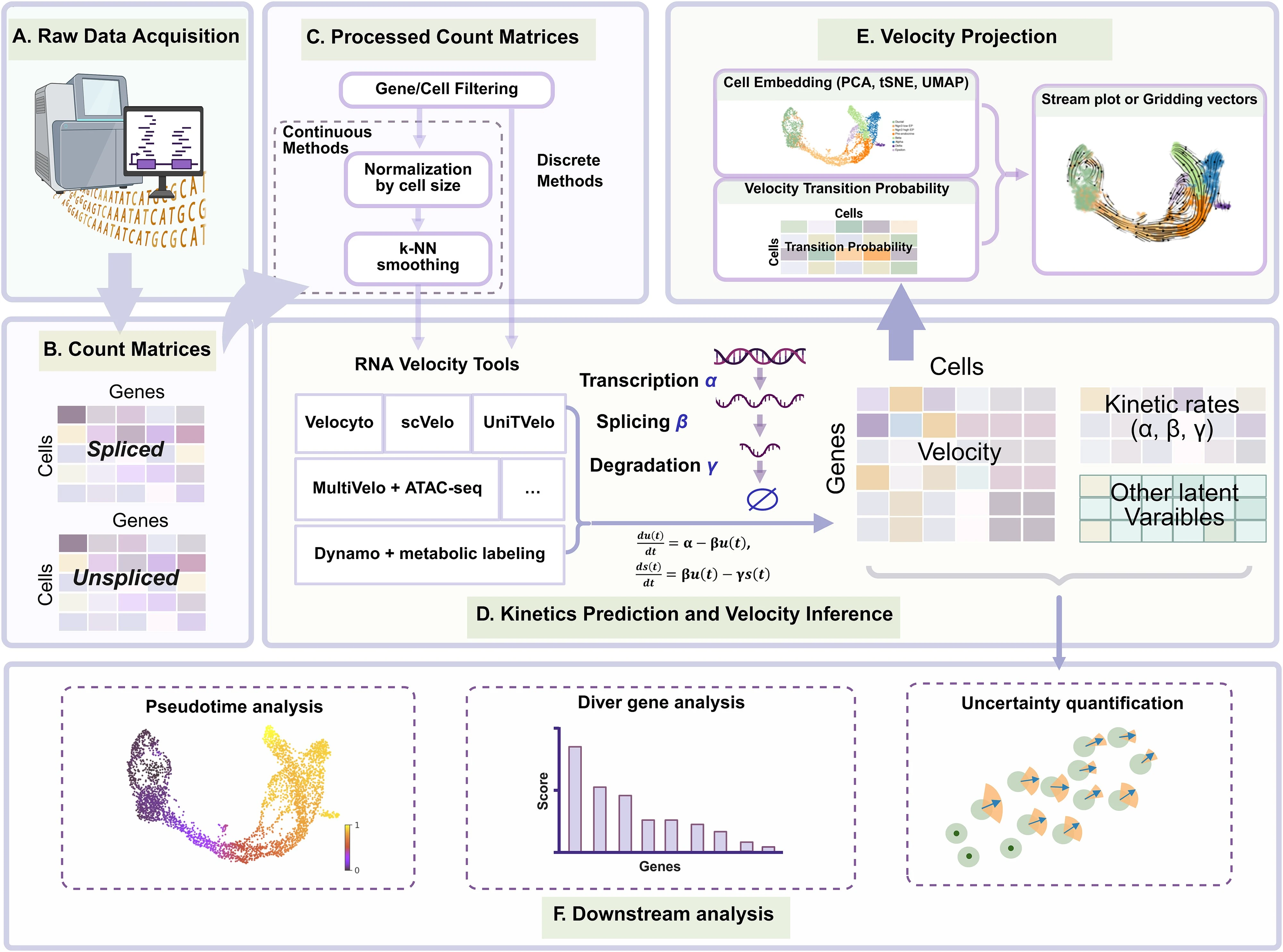
Methodological Paradigms
The sources categorize RNA velocity computational tools into three primary classes based on how they infer transcriptional kinetics:
- Steady-state Methods (e.g., Velocyto): These assume that gene expression reaches an equilibrium between synthesis and degradation; they are often faster and simpler but can be inaccurate if the system has not reached a steady state
- Trajectory Methods (e.g., scVelo Dynamical, UniTVelo): These fit the full transcriptional cycle using systems of ordinary differential equations (ODEs) to estimate latent time and gene-specific kinetic parameters
- State Extrapolation Methods (e.g., cellDancer, DeepVelo): These focus on local cell-specific kinetics by leveraging neighboring cell information to capture subtle variations across heterogeneous populations
Biological Applications
RNA velocity has provided quantitative insights across three major biological scenarios:
- Developmental Biology: It helps resolve complex lineage hierarchies and temporal sequences in systems like embryonic development, neural stem cell differentiation, and retinal maturation
- Diseased and Injured Environments: The technique identifies abnormal cellular transitions in conditions such as Alzheimer’s disease, systemic lupus erythematosus, and impaired tissue regeneration
- Tumor Microenvironments: Researchers use it to dissect cancer cell plasticity, immune cell exhaustion trajectories, and the dynamic interactions between malignant cells and their surroundings
Critical Challenges and Limitations
Despite its utility, the sources highlight significant technical and theoretical hurdles:
- Biophysical Inconsistency: Current binary models (spliced vs. unspliced) oversimplify biology, as most human genes have multiple introns and complex alternative splicing mechanisms
- Inaccurate Assumptions: Many models rely on constant kinetic rates, which fail to account for “transcriptional boosts” or multi-rate regimes where splicing or degradation speeds vary over time
- Preprocessing Pitfalls: Common steps like normalization and k-nearest neighbor (KNN) smoothing can introduce distortions, create false signals, or obscure the stochastic nature of gene expression
- Visualization Artifacts: Projecting high-dimensional velocity vectors onto 2D embeddings (like UMAP or t-SNE) frequently distorts local and global relationships, leading to misleading biological interpretations
Future Directions and Proposed Solutions
To improve the reliability of RNA velocity, the sources propose several innovations: - Stochastic and Discrete Modeling: Moving away from continuous ODEs toward discrete Markov models (e.g., using the Chemical Master Equation) to better handle low-copy number transcripts and “bursty” transcription - Multi-modal Integration: Incorporating other data layers, such as chromatin accessibility (ATAC-seq), metabolic labeling, or protein abundance, to provide a more comprehensive view of cellular dynamics - State-Variable Kinetics: Developing models that allow kinetic rates to change as a cell moves through different biological states
Gorin et al. (2022) Bergen et al. (2021) Y. Wang et al. (2025)
Preprocessing choices affect RNA velocity results for droplet scRNA-seq data Soneson et al. (2021)
- Velocyto (Python,R)
- scVelo (Python)
- SDEvelo (Python) Multivariate stochastic modeling
- MultiVelo (Python) Velocity Inference from Single-Cell Multi-Omic Data
- UniTVelo (Python) Temporally Unified RNA Velocity
- DeepVelo (Python) Deep learning for RNA velocity
- VeloAE (Python) Low-dimensional Projection of Single Cell Velocity
- GeneTrajectory (R) R implementation of GeneTrajectory
- TFvelo Gene regulation inspired RNA velocity estimation
- DeepCycle (Python) Cell cycle inference in single-cell RNA-seq
- velocycle (Python) Bayesian model for RNA velocity estimation of periodic manifolds
2.12 Metacells
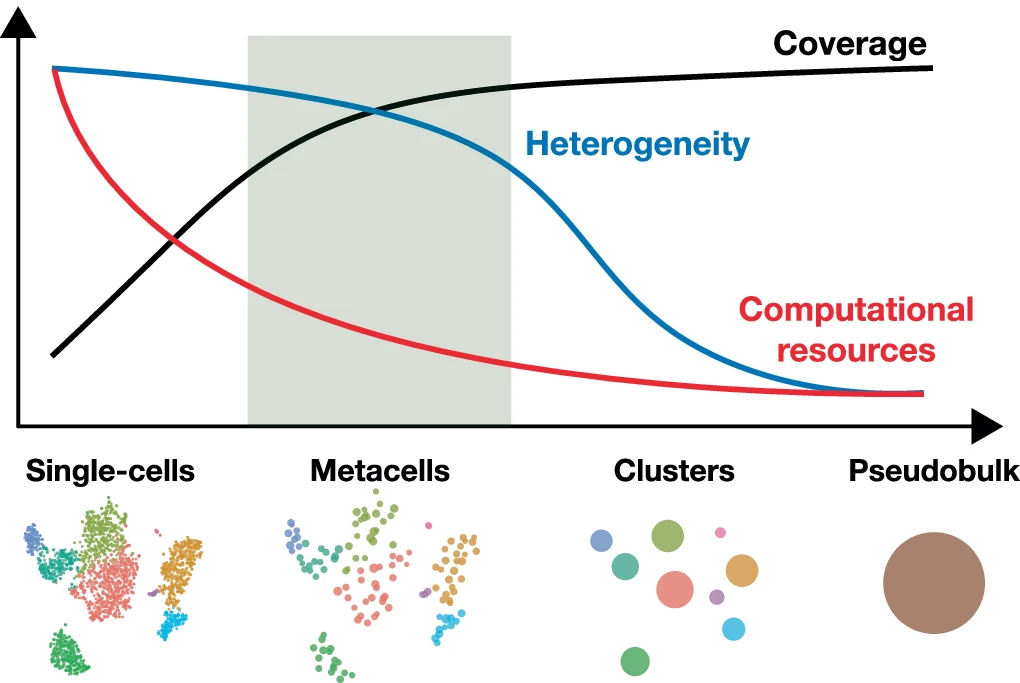
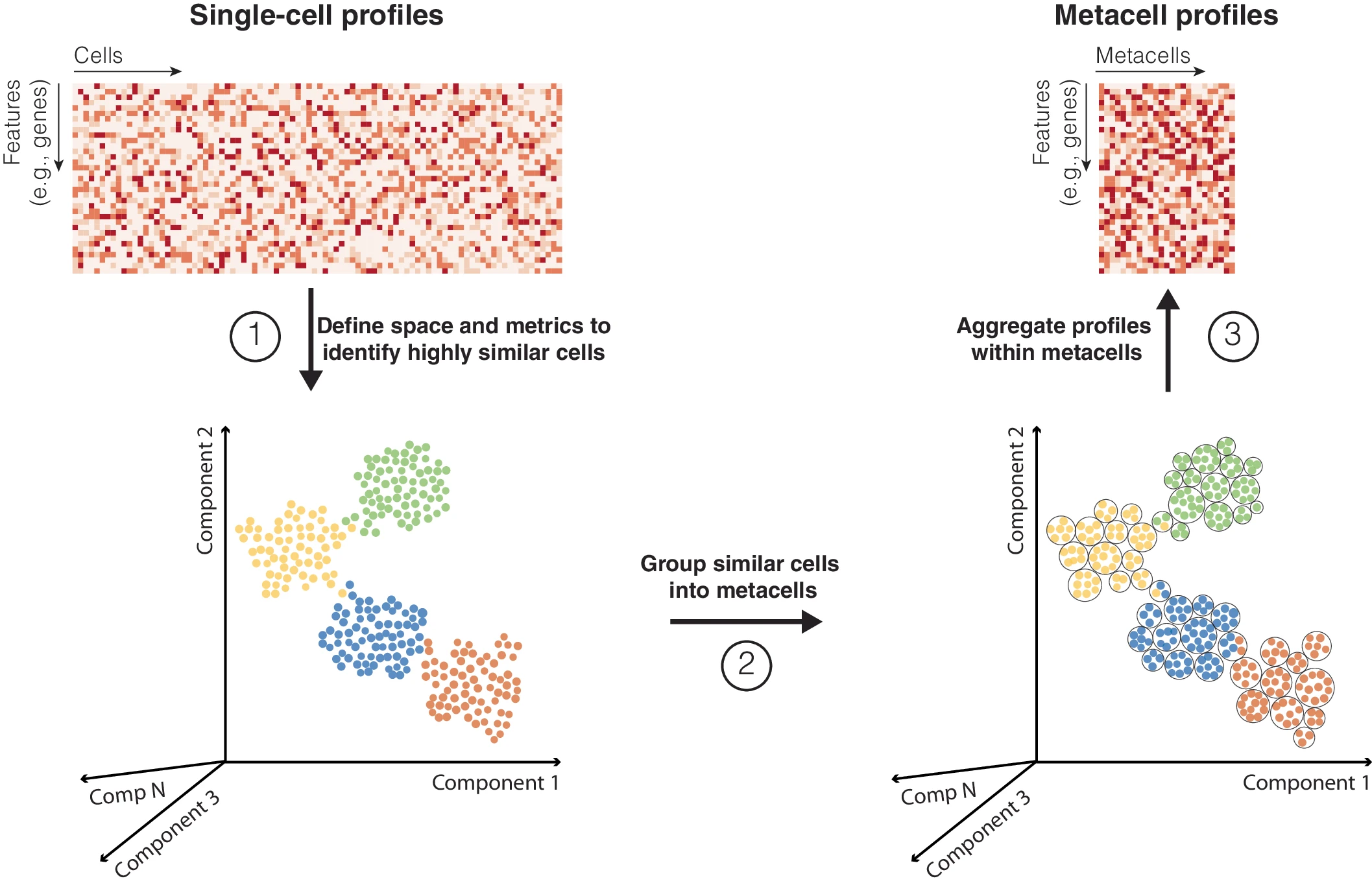
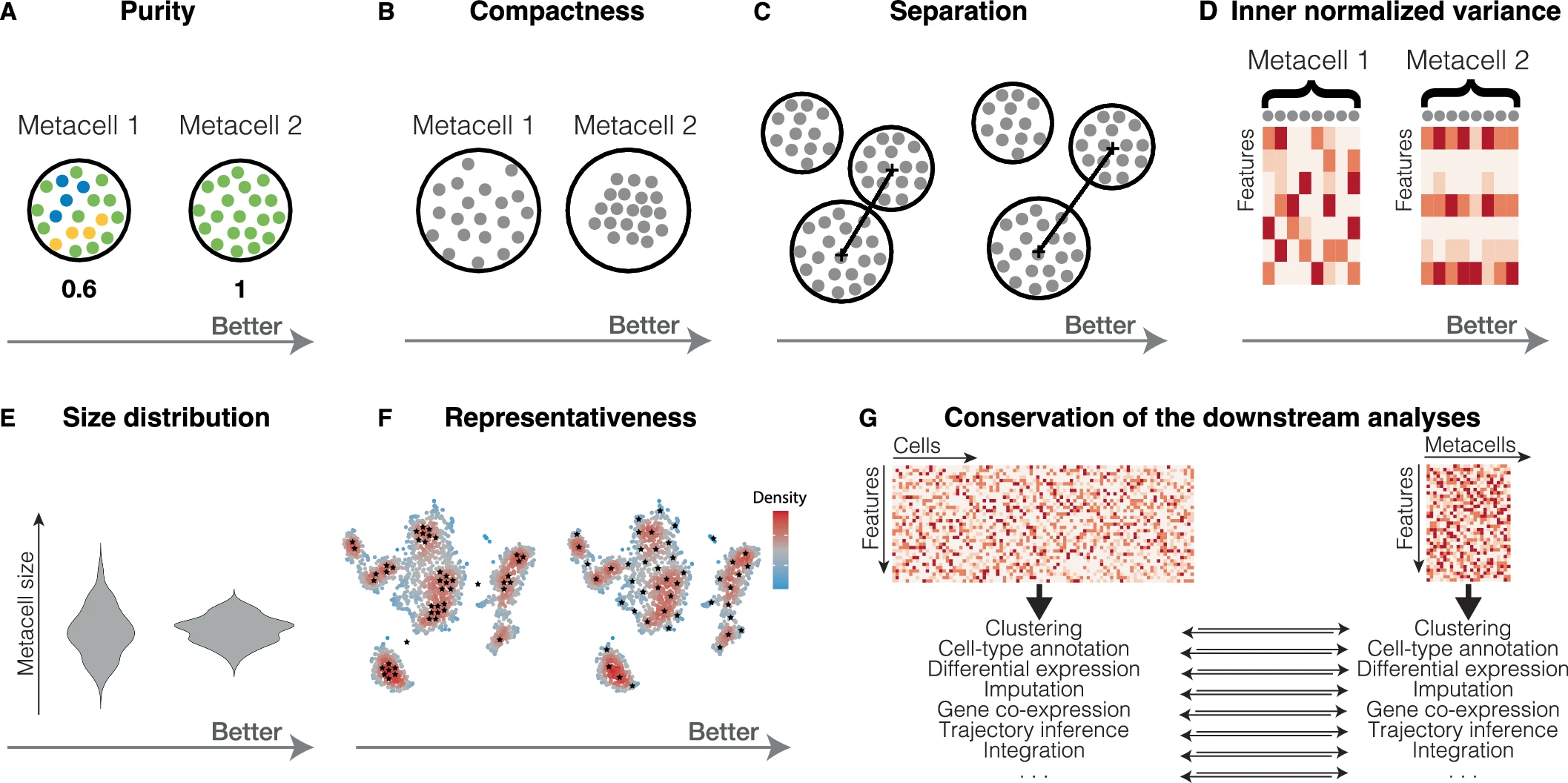
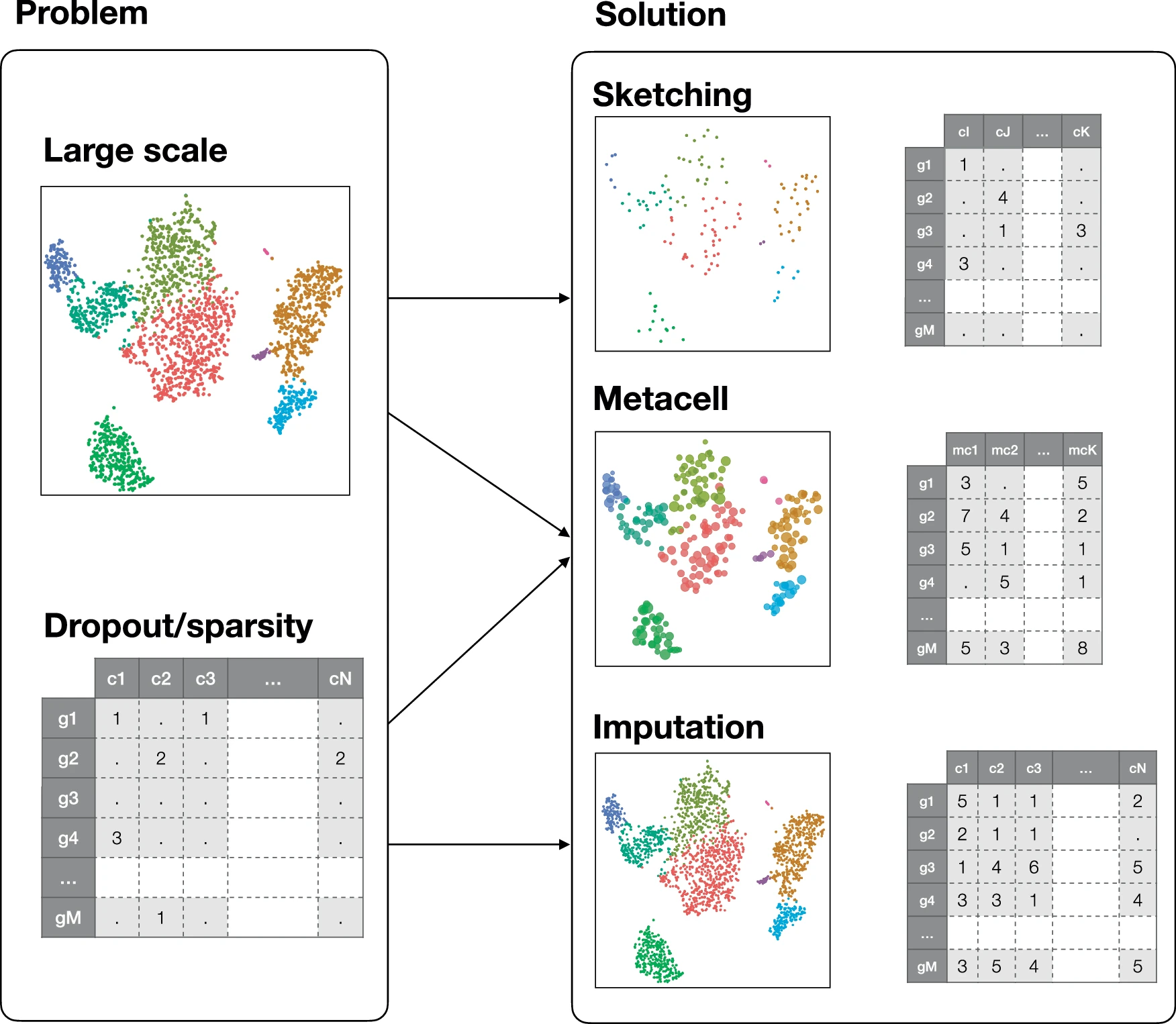
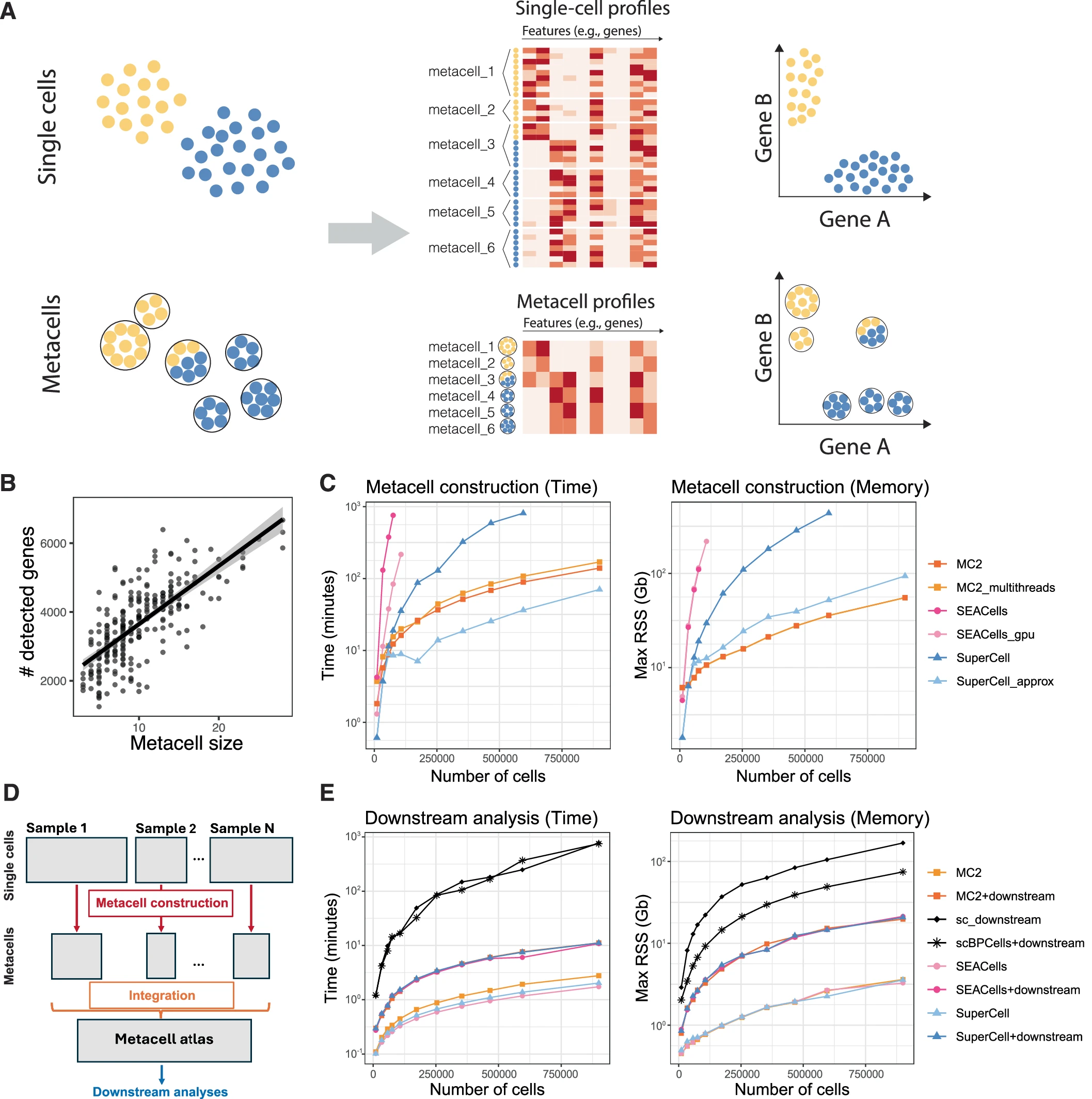
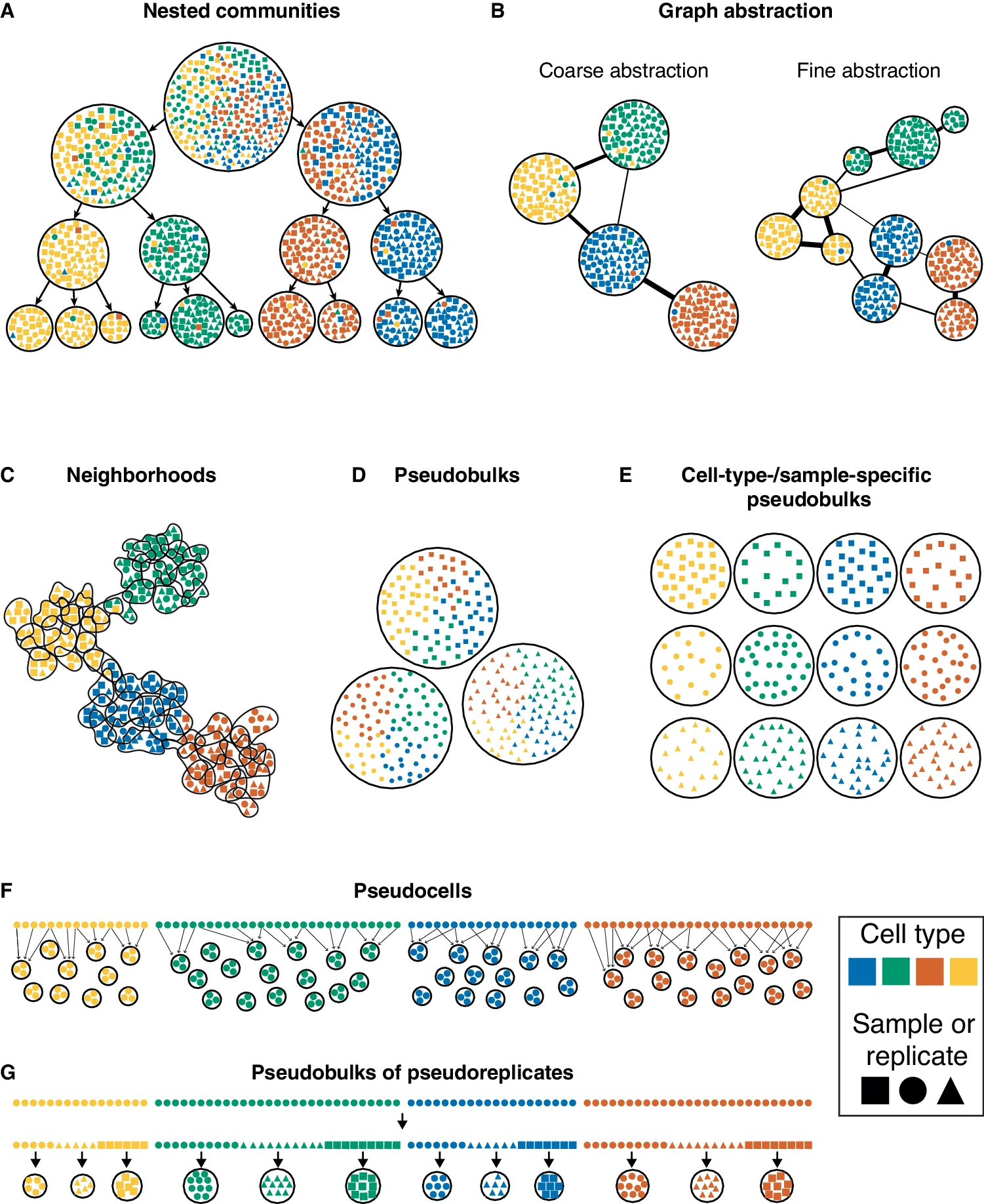
Metacells are defined as a partition of single-cell data into disjoint homogeneous groups of highly similar cells followed by aggregation of their profiles. This concept relies on the assumption that most of the variability within metacells corresponds to technical noise and not to biologically relevant heterogeneity. As such, metacells aim at removing some of the noise while preserving the biological information of the single-cell data and improving interpretability.
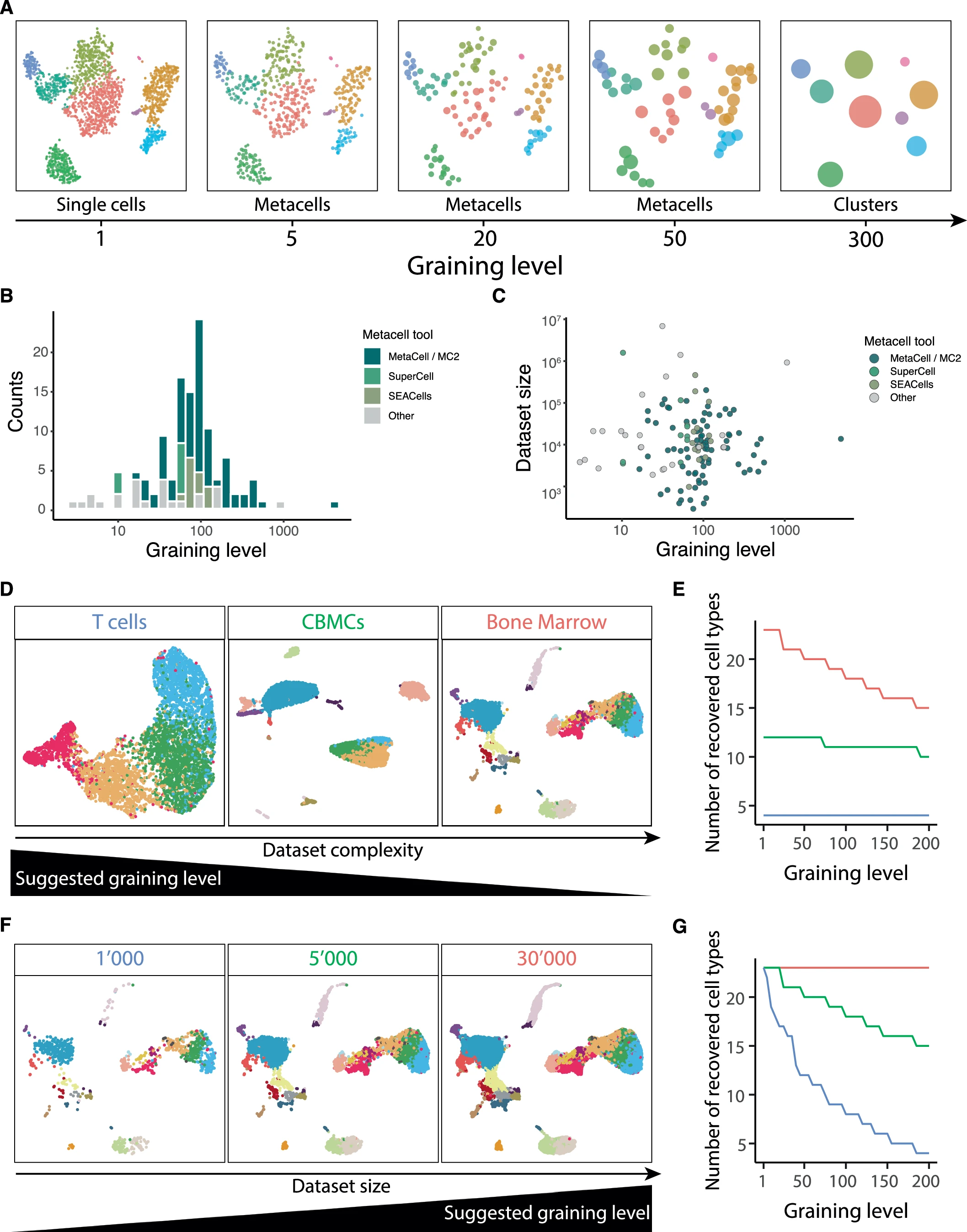
- Choice of graining levels depends on both the complexity and size of the data
- For large and low-complexity data, a relatively high graining level may be used.
- For higher complexity or lower size, use lower graining levels to preserve the underlying heterogeneity
- Choose graining levels such that the resulting number of metacells is at least ten times larger than the expected number of cell subtypes.
- Somewhere between 10 and 50
- Optimal graining is hard to evaluate using measures such as modularity or silhouette coefficient
- Number of nearest neighbors
- Increasing k results in a more uniform distribution of metacell sizes
- Excessively large values of k (e.g., ~100) may lead to the merging of rare cell types
- Reasonable range of values 5–30
2.12.1 Metrics
- Purity: Fraction of cells from the most abundant cell type in a metacell
- to check that metacells do not mix cells from different cell types
- Compactness: A measure of a metacell’s homogeneity that helps flag low-quality metacells for review. Its value is dependent on the latent space used.
- SEACells and SuperCell using PCA space will perform better than MetaCell and MC2 which uses normalized gene space
- Separation: Euclidean distance between centroids of metacells
- There is also a clear relationship between separation and compactness. Better compactness results in worse separation and vice versa. Metacells from dense regions will have better compactness but worse separation, while metacells from sparse regions will have better separation but worse compactness.
- INV: mean normalized variance of features. Minimal is better
- INV should be proportional to its mean
- Size: Number of single cells per metacell
- To ensure balanced downstream analyses, it is better to have a more homogeneous metacell size distribution and avoid significant outliers
- Representativeness: A good metacell partition should reproduce the overall structure (i.e., manifold) of the single-cell data by uniformly representing its latent space
- a more uniform representativeness of the manifold leads to increased variation in metacell sizes to compensate for inherent over- and under-representation of different cell types.
- Conservation of downstream analysis
- Clustering assignment obtained at the metacell and single-cell levels can be compared using adjusted rand index (ARI) or adjusted mutual information (AMI).
- metacell concept is used to enhance signal for GRN construction
By aggregating information from several highly similar cells, metacells reduce the size of the dataset while preserving, and possibly even enhancing, the biological signal. This simultaneously addresses two main challenges of single-cell genomics data analysis: the large size of the single-cell data and its excessive sparsity.
Trade-off between topology-preserving downsampling (sketching) and imputation.
2.12.2 Limitations
- The metacell partition may be considered a very high-resolution clustering.
- metacells do not guarantee a global convergence.
- potentially group cells of distinct types within a single metacell (impure metacells)
- Artifacts can lead to misleading interpretations, including the presence of non-existing intermediate states or spurious gene co-expression
- rare cell types could be completely missed if entirely aggregated with a more abundant cell type into a single metacell.
- build metacells in a supervised manner by constructing metacells for each cell type separately
Adding cells per metacell as covariate
Bilous et al. (2024)
- metacell (R)
- metacells (Python)
- SuperCell (R)
- SEACells (Python)
- MATK: Meta Cell Analysis Toolkit (Bash)
Gfeller Lab tutorial
2.13 Cell communication
Cell-cell communication and interaction.
Review of tools Almet et al. (2021)
2.14 Databases
2.14.1 Data
Single-cell data repositiories.
2.14.2 Markers
Curated list of marker genes by organism, tissue and cell type.
2.15 Tools
2.15.1 CLI frameworks
- Scanpy (Python)
- Seurat (R)
- Bioconductor (R)
- Scarf (Python) Atlas scale analysis
- Cumulus Cloud computing
2.15.2 Interactive analysis/visualisation
2.15.2.1 Open source
- Galaxy (GUI)
- Kana (GUI)
- UCSC Cell Browser (GUI)
- cellxgene (GUI)
- ShinyCell(R Shiny)
- Cerebro(R Shiny)
- Vitessce(R, Python)
- CDCP
- SingleCellVR
- Loupe 10X Loupe browser for CellRanger/Spaceranger outputs
- LoupeR Seurat to Loupe format. Supports only GEX assay.

Ouyang et al. (2021)
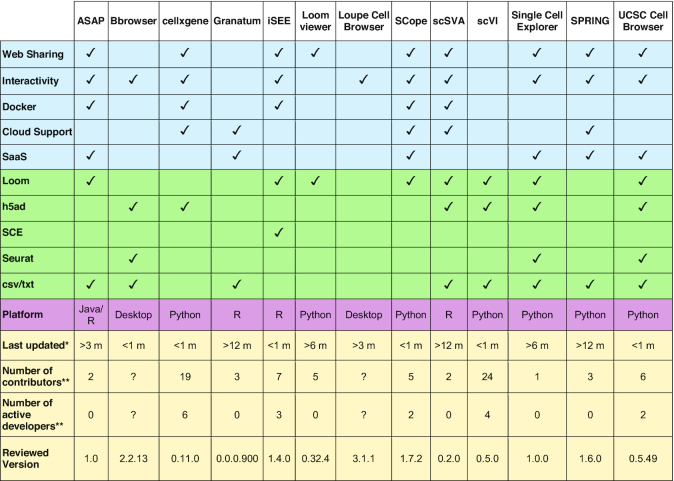
Cakir et al. (2020)
2.15.2.2 Commercial
Enterprise GUI solutions for single-cell data analysis.
- Parktek Flow
- Qiagen CLC Genomics
- Parse Trailmaker (Free for Academia and Parse users)
- Nygen
- Rosalind.Bio
- BioTuring
- BioInfoRx